LK06(Brahman)에서는 Linux 커널의 기능 중 하나인 eBPF에 포함된 JIT(검증기)의 버그를 공격합니다. 이 장에서는 먼저 BPF라는 기능과 그 사용법에 대해 배웁니다.
BPF
eBPF에 대해 설명하기 전에, 그 전신인 BPF에 대해 설명합니다.
BPF는 시대와 함께 사용 용도가 넓어지고, 확장이 진행되었습니다. 대폭적인 변경이 들어간 후의 BPF를 eBPF(extended BPF), 그 이전의 BPF를 cBPF(classic BPF)라고 구별하여 표기하기도 합니다. 하지만 현재의 Linux에서는 내부적으로 eBPF만이 이용되고 있기 때문에, 본 사이트에서는 명확하게 구별이 필요하지 않을 때는 eBPF/cBPF를 묶어서 BPF라고 부릅니다.
BPF란?
BPF(Berkeley Packet Filter)란, Linux 커널이 가진 독자적인 RISC형 가상 머신입니다. 사용자 공간에서 전달된 코드를 커널 공간에서 실행하기 위해 준비되어 있습니다. 당연히 임의의 코드가 실행되면 위험하기 때문에, BPF에 존재하는 명령어 집합은 연산이나 조건 분기와 같은 안전한 명령어가 대부분입니다. 하지만 메모리 쓰기나 점프 등의 안전성이 보장되지 않는 명령어도 포함되어 있기 때문에, 바이트코드를 수리할 때 **검증기(Verifier)**를 통과시킵니다. 이를 통해 (예를 들어 무한 루프에 빠지지 않는 것 같은) 안전한 프로그램만 실행할 수 있습니다.
그렇다면 왜 이렇게까지 해서 사용자 공간에서 커널 공간으로 코드를 실행할 필요가 있는 것일까요?
BPF는 설계 당초 패킷 필터링을 목적으로 만들어졌습니다. 사용자가 BPF 코드를 로드해 두면, 통신 패킷이 발생한 타이밍에 BPF 코드가 실행되어 필터링에 이용할 수 있습니다. 현재는 패킷 필터링 이외에도, 실행 추적(Trace)의 취득이나, seccomp가 시스템 콜을 필터링하는 구조 등에도 BPF가 이용되고 있습니다.
이처럼 패킷 필터나 seccomp 등, 다양한 곳에서 BPF가 이용되게 되었습니다. 하지만 매번 BPF 바이트코드를 해석하여 에뮬레이트해서는 실행 속도에 문제가 있습니다. 그래서 검증기를 통과한 BPF 바이트코드는, JIT(Just-in-Time) 컴파일러에 의해 CPU가 해석할 수 있는 기계어로 변환됩니다.
JIT 컴파일러란, 프로그램의 실행 중 등 동적으로, 무언가의 코드를 네이티브 기계어로 변환해 주는 기구를 가리킵니다. 예를 들어 Chrome이나 Firefox 등의 브라우저는 몇 번이나 호출되는 JavaScript 함수를 발견하면, 그것을 기계어로 변환하여 이후에는 기계어 쪽을 실행함으로써 고속화하고 있습니다. Linux 커널의 BPF에서 JIT 컴파일러가 이용될지는 옵션 나름이지만, 현재의 Linux 커널에서는 표준으로 JIT 컴파일러가 활성화되어 있습니다.
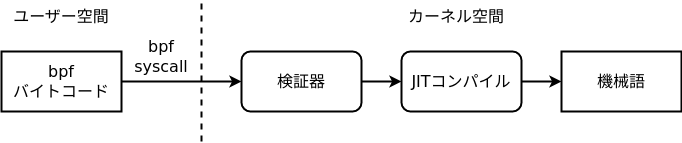
정리하면, BPF 코드가 실행되기까지의 흐름은 다음과 같습니다.
- 사용자 공간에서 bpf 시스템 콜로 BPF 바이트코드가 커널 공간에 전달된다.
- 바이트코드를 실행해도 안전한가를 검증기가 확인한다.
- 검증에 성공하면, JIT 컴파일러로 CPU에 대응한 기계어로 변환한다.
- 이벤트가 발생하면, JIT 컴파일 후의 기계어가 호출된다.
이벤트가 발생하면, 등록한 BPF(체크하고 싶은 이벤트)의 종류에 따라 인수가 전달됩니다. 이 인수를 컨텍스트라고 부릅니다. BPF는 그 인수를 처리하여 최종적으로 1개의 반환값을 반환합니다. 예를 들어 seccomp의 경우, 호출되려고 하는 시스템 콜의 번호나 아키텍처의 종류 등이 들어간 구조체가 인수로 BPF 프로그램에 전달됩니다. BPF 프로그램(seccomp filter)은 시스템 콜 번호 등을 바탕으로 시스템 콜의 실행을 허가할지 등을 판단하고, 반환값으로 커널에 전달합니다. 이 반환값을 받은 커널은 시스템 콜을 허가할지, 거부할지, 아니면 실패하게 할지 등을 판단할 수 있습니다.

seccomp는 지금도 cBPF를 사용하고 있지만, 커널 내부에서는 eBPF밖에 사용하지 않기 때문에, 처음에 eBPF로 변환돼. 그리고 seccomp에는 BPF 검증기에 더해 독자적인 검증 기구가 있어.
또한, BPF 프로그램과 사용자 공간이 통신하기 위해서는 BPF 맵이라는 것을 사용합니다. BPF에서는 커널 공간에 맵이라는 key-value 쌍의 연관 배열[1]을 만들 수 있습니다. 이에 대한 자세한 내용은 실제로 BPF 프로그램을 작성할 때 살펴봅니다.
BPF 아키텍처
보다 자세히 BPF의 구조를 살펴봅시다. cBPF는 32비트 아키텍처였지만, eBPF에서는 최근 아키텍처에 맞춰 64비트가 되었고, 레지스터의 수도 늘어났습니다. 여기서는 eBPF의 아키텍처를 설명합니다.
레지스터와 스택
BPF 프로그램에서는 512바이트의 스택을 이용할 수 있습니다. eBPF에서는 다음과 같은 레지스터가 준비되어 있습니다.
| BPF 레지스터 | 대응하는 x64 레지스터 |
|---|---|
| R0 | rax |
| R1 | rdi |
| R2 | rsi |
| R3 | rdx |
| R4 | rcx |
| R5 | r8 |
| R6 | rbx |
| R7 | r13 |
| R8 | r14 |
| R9 | r15 |
| R10 | rbp |
R10 이외의 레지스터는 BPF 프로그램 중에서 범용 레지스터로서 취급할 수 있지만, 몇 가지 특수한 의미를 가진 레지스터가 있습니다.
우선, 커널 측에서 전달되는 컨텍스트(포인터)가 R1에 들어갑니다. BPF 프로그램은 통상 이 컨텍스트의 내용을 처리하게 됩니다. 예를 들어 소켓 필터의 경우 컨텍스트에서 패킷 데이터를 꺼내는 등이 가능합니다.
그리고 R0 레지스터는 BPF 프로그램의 반환값으로 이용됩니다. 그렇기 때문에 BPF 프로그램을 종료(BPF_EXIT_INSN)하기 전에 반드시 R0에 값을 설정해야 합니다. 종료 코드에는 의미가 있으며, 예를 들어 seccomp의 경우는 시스템 콜을 허가/거부할지 등을 나타냅니다.
다음으로 R1에서 R5는 커널 내의 함수(후술할 헬퍼 함수)를 BPF 프로그램에서 호출할 때의 인수 레지스터로 이용됩니다.
마지막으로 R10은 스택의 프레임 포인터로, 읽기 전용이 되어 있습니다.
명령어 집합
일반 사용자가 로드하는 BPF 프로그램은 최대 4096 명령[2]을 사용할 수 있습니다.
BPF는 RISC형 아키텍처이므로 모든 명령은 같은 크기로 되어 있습니다. 각 명령은 64비트이며, 다음과 같이 각 비트가 의미를 가집니다.
| 비트 | 이름 | 의미 |
|---|---|---|
| 0-7 | op |
오퍼코드 |
| 8-11 | dst_reg |
대상 레지스터 |
| 12-15 | src_reg |
소스 레지스터 |
| 16-31 | off |
오프셋 |
| 32-63 | imm |
즉시값 |
오퍼코드 op는 처음 4비트가 코드, 다음 1비트가 소스, 남은 3비트가 클래스를 나타냅니다.
클래스는 명령의 종류(메모리 쓰기, 산술 연산 등)를 지정합니다. 소스는 소스 오퍼랜드가 레지스터인지 즉시값인지를 결정합니다. 그리고 코드가 클래스 중의 구체적인 명령 번호를 지정합니다.
BPF의 명령어 집합은 Linux 커널 문서에 기재되어 있습니다.
프로그램 타입
앞의 예에서 실제로 BPF를 테스트했을 때는 BPF_PROG_TYPE_SOCKET_FILTER라는 타입을 지정했습니다. 이처럼 BPF 프로그램을 어떤 용도로 사용할지를 로드 시에 지정해야 합니다.
cBPF에서는 소켓 필터와 시스템 콜 필터의 2종류밖에 없었지만, eBPF에서는 20개 이상의 타입이 준비되어 있습니다.
타입 일람은 uapi/linux/bpf.h에 정의되어 있습니다.
예를 들어 BPF_PROG_TYPE_SOCKET_FILTER는 cBPF에서도 사용할 수 있는 소켓 필터 용도입니다. BPF 프로그램의 반환값에 따라 패킷을 드롭하는 등의 조작이 가능합니다. 이 타입의 BPF 프로그램은 SO_ATTACH_BPF 옵션으로 setsockopt 시스템 콜을 호출함으로써 소켓에 어태치(Attach)할 수 있습니다.
컨텍스트로서 __sk_buff 구조체가 전달됩니다.

Linux 커널의 sk_buff 구조체를 그대로 전달하면 커널 버전에 의존해 버리니까, BPF용으로 구조를 맞추고 있어.
헬퍼 함수
레지스터 항목에서 조금 설명이 있었던 것처럼, BPF 프로그램에서 호출할 수 있는 함수가 있습니다. 예를 들어 소켓 필터의 경우, 기본이 되는 헬퍼 함수에 더해 4개의 함수가 제공되고 있습니다.
1 | static const struct bpf_func_proto * |
기본이 되는 헬퍼 함수에는 BPF 맵을 다루는 map_lookup_elem이나 map_update_elem 등이 있습니다. 각 함수의 구체적인 사용법은 실제로 BPF 프로그램을 작성하면서 배웁시다.
BPF 이용
그러면 실제로 BPF(eBPF)를 이용해 봅시다.
LK06 머신상에서 테스트하는 경우는 문제없습니다만, 여러분이 사용하고 있는 머신에서 테스트하는 경우는 먼저 BPF를 일반 사용자가 사용할 수 있는지를 확인해 주세요. 이 기사를 쓴 시점에서는 Spectre 등의 사이드 채널 공격 방지를 위해 일반 사용자로부터는 BPF를 이용할 수 없게 되어 있습니다. 활성화 여부는 /proc/sys/kernel/unprivileged_bpf_disabled에서 확인할 수 있습니다.
1 | $ cat /proc/sys/kernel/unprivileged_bpf_disabled |
이 값이 0이라면 CAP_SYS_ADMIN을 가지고 있지 않은 사용자도 BPF를 이용할 수 있습니다. 1이나 2로 되어 있는 경우는 일시적으로 0으로 다시 씁시다.
BPF 프로그램 작성
패킷 필터링 등 복잡한 코드를 작성할 경우는, 보통 BCC 같은 컴파일러를 사용하여 C언어 등 보다 고급 언어로 기술합니다. 이번에는 exploit 목적으로 가볍게 사용할 뿐이므로, 컴파일러를 사용하지 않고 BPF 바이트코드를 직접 기술해 봅시다. 직접이라고 해도 바이트코드를 16진수로 쓰는 것은 아닙니다. 어셈블리 언어처럼 인간이 알기 쉬운 형태로 쓸 수 있는 C언어용 매크로가 준비되어 있습니다.
우선 이 매크로가 정의된 bpf_insn.h를 다운로드하여 테스트용 C 코드와 같은 폴더에 넣어 둡시다.
우선은 아무것도 하지 않는 BPF 프로그램을 실행해 봅니다.
1 |
|
이 코드에서는 소켓에 대해 BPF 프로그램을 로드(BPF_PROG_TYPE_SOCKET_FILTER)합니다. 그 때문에 마지막 write를 트리거로 BPF 프로그램이 실행됩니다.
아래 부분이 BPF 프로그램이 됩니다.
1 | struct bpf_insn insns[] = { |
이 예에서는 R0에 64비트 즉시값 4를 대입하고, 프로그램을 종료합니다. 정상적으로 동작했을 경우 "Hell"이라고 출력될 것입니다.
레지스터에 대해서는 나중에 자세한 설명이 있지만, R0 레지스터는 BPF 프로그램의 반환값으로 이용됩니다. 이번 write로 5문자 송신했음에도 불구하고 4문자밖에 수신되지 않은 것은, BPF가 패킷을 드롭했기 때문입니다. 즉, 반환값에 의해 송신 데이터를 컷할 수 있는 것입니다. 실제로 socket 매뉴얼에는 다음과 같이 쓰여 있습니다.
SO_ATTACH_FILTER (since Linux 2.2), SO_ATTACH_BPF (since Linux 3.19)
Attach a classic BPF (SO_ATTACH_FILTER) or an extended BPF (SO_ATTACH_BPF) program to the socket for use as a filter of incoming packets. A packet will be dropped if the filter program returns zero. If the filter program returns a nonzero value which is less than the packet’s data length, the packet will be truncated to the length returned. If the value returned by the filter is greater than or equal to the packet’s data length, the packet is allowed to proceed unmodified.
BPF 맵의 이용
여기까지 BPF를 사용하여 패킷을 필터링할 수 있음을 확인했습니다.
다음으로, eBPF exploit에서 반드시라고 해도 좋을 만큼 이용하는 BPF 맵을 사용해 봅니다. 사용자 공간(BPF 프로그램을 로드한 쪽)과 커널 공간에서 동작하는 BPF 프로그램이 통신하기 위해 BPF 맵이 이용됩니다.
BPF 맵을 만들려면 BPF_MAP_CREATE로 bpf 시스템 콜을 호출합니다. 이때 전달하는 bpf_attr 구조체는 타입을 BPF_MAP_TYPE_ARRAY로 하고, 배열의 크기나 키/값의 크기를 지정합니다. exploit 문맥에서는 키가 작아도 되므로, 키는 int형으로 고정합니다.
1 | int map_create(int val_size, int max_entries) { |
배열 내 값의 갱신은 BPF_MAP_UPDATE_ELEM, 취득은 BPF_MAP_LOOKUP_ELEM으로 실현할 수 있습니다.
1 | int map_update(int mapfd, int key, void *pval) { |
다음과 같은 프로그램으로 동작을 확인해 보세요. 맵의 값을 (사용자 공간에서) 읽고 쓸 수 있는 것을 알 수 있을 것입니다.
1 | unsigned long val; |
그럼 다음으로 BPF 맵을 BPF 프로그램 측에서 조작해 봅니다.
1 | /* BPF 맵 준비 */ |
이 BPF 프로그램은 map_update_elem 헬퍼 함수를 이용해 BPF 맵의 키 1의 값을 0x1337로 변경합니다.
먼저, map_update_elem에는 키와 값 모두 포인터를 전달하므로 메모리상에 키와 값을 준비합니다.
1 | BPF_ST_MEM(BPF_DW, BPF_REG_FP, -0x08, 1), // key=1 |
BPF_REG_FP는 R10을 의미하며, 스택 포인터가 됩니다. BPF_ST_MEM은 익숙하 x86-64 어셈블리로 쓰면 다음과 같습니다.
1 | mov dword [rsp-0x08], 1 |
다음에 인수를 준비합니다. 인수는 BPF_REG_ARG1에서 순서대로 넣는데, 이것은 R1부터의 레지스터입니다.
map_update_elem의 첫 번째 인수는 BPF 맵의 파일 디스크립터입니다. BPF_LD_MAP_FD를 사용하여 레지스터에 대입할 수 있습니다.
1 | // arg1: mapfd |
두 번째 인수와 세 번째 인수는 각각 키, 값에 대한 포인터입니다.
1 | // arg2: key pointer |
네 번째 인수는 플래그인데, 0을 넣어 둡니다.
1 | // arg4: flags |
마지막으로 BPF_EMIT_CALL을 사용하여 헬퍼 함수를 호출할 수 있습니다.
1 | BPF_EMIT_CALL(BPF_FUNC_map_update_elem), // map_update_elem(mapfd, &k, &v) |
실행하면 BPF 프로그램이 발화하는 write 명령 전후로 BPF 맵 중의 키 1의 값이 변화하고 있는 것을 알 수 있습니다.
1 | $ ./a.out |
여기까지 BPF의 기초는 끝입니다. 이처럼 BPF 프로그래밍에서는 BPF 맵이나 헬퍼 함수를 구사하여 패킷 필터 등을 구현할 수 있습니다.
다음 장에서는 BPF 관련 취약점에서 가장 핵심이 되는 검증기에 대한 이야기를 합니다.
skb_load_bytes 등의 헬퍼 함수를 조사한다.)(1) 송신 데이터에 "evil"이라는 문자열이 포함되어 있으면 드롭한다.
(2) 송신 데이터 사이즈가 4바이트 이상인 경우, 선두 4바이트를 "evil"로 변경한다.